「安全運転なら保険料が安くなる」と聞くと、多くの人は直感的に公平だと感じるかもしれません。事故を起こす可能性が低い人がより少ない負担で済むという仕組みは合理的にも思えます。一方で、テレマティクス保険は車載機器やスマートフォンを通じて運転データを取得し、その内容をもとに保険料を算定します。ブレーキの頻度や急加速の有無、走行時間帯などが記録されることもあり、この「常時データ取得」という構造に違和感を抱く人もいます。データ活用が進む社会において保険もまた変化していますが、この仕組みは本当に公平性を高めているのでしょうか。本記事では賛否を急がず、その構造を整理します。
従来型保険の公平性とは何だったのか
属性に基づくリスク分類
従来の自動車保険では、年齢・性別・等級・地域などの属性がリスク分類の基準とされてきました。これは過去の事故統計をもとに、特定の集団がどの程度の事故率を持つかを推計する仕組みです。
このような方法は「統計的公平」とも呼ばれます。個人ではなく集団単位でリスクを評価し、その平均値を保険料に反映させる考え方です。
なぜ不公平と感じられてきたのか
20代という理由だけで保険料が高く設定される場合、実際に慎重に運転している人にとっては自分の行動が評価されていないと感じられることがあります。
この違和感は、集団単位の公平と個人単位の公平のズレから生じます。従来型保険は相互扶助の原理に基づきつつも、個々の事情を十分に反映できないという構造を持っていました。
テレマティクス保険がもたらす新しい公平
行動に基づく個別評価
テレマティクス保険では、実際の運転行動が評価対象になります。これは属性ではなく行動データに基づく個別評価への転換と言えます。
ここでは事故という結果だけでなく、運転の過程が評価されます。急ブレーキや速度超過といった具体的行動がスコア化され、それが保険料に反映される場合もあります。
情報の非対称性の変化
従来、保険会社は契約者の実際の運転状況を詳細には把握できませんでした。これを「情報の非対称性」と呼びます。つまり契約者のほうが自分のリスクをよく知っている状態です。
テレマティクス保険はこの非対称性を縮小させます。保険会社がより多くの情報を得ることでリスク評価の精度が高まる可能性があります。同時に契約者側も自らの運転傾向を可視化できるという側面があります。
見落とされがちな新たな不公平
測定可能な行動だけが評価される構造
データ化できる行動だけが評価対象になるという構造もあります。慎重な判断や周囲への配慮といった要素は数値化が難しい場合があります。
評価可能性そのものが、何を良い運転とみなすかを規定してしまう可能性もあります。
構造的条件の反映
夜間勤務者や長距離通勤者は、走行距離や時間帯の影響でリスクが高く評価される場合があります。これは個人の努力では変えにくい条件がリスクとして反映される構造です。
行動ベースの評価もまた、社会的条件を内包していると言えます。
プライバシーと自己責任の接続
常時データ取得はプライバシーとの緊張関係を伴います。どこまでの情報が収集され、どのように利用されるのかは重要な論点です。
さらに「正しく行動すれば安くなる」という仕組みは、「正しく行動しないのは自己責任」という解釈に接続する可能性もあります。公平性の高度化が責任の個人化を強める方向に働くかどうかは、制度設計に左右されます。
公平性とは誰にとっての公平か
個人単位と社会全体の視点
個人単位の公平とは、各人のリスクに応じて負担が調整されることです。一方で社会全体の公平とは、リスクを広く分散し誰もが加入しやすい環境を維持することでもあります。
保険の本質は相互扶助とリスク分散にあります。過度に個別化された評価が進むと、リスクの高い人が排除される可能性も考えられます。
データ社会における評価は効率性と包摂性のあいだで揺れ動きます。テレマティクス保険もまた、その一断面と捉えることができます。
まとめ
テレマティクス保険は従来型よりも個別化された評価を可能にする仕組みです。その点である種の公平を強化する側面があります。
同時に測定可能性への依存やプライバシーの問題、自己責任の強化といった新たな論点も生み出しています。
この制度を単純に公平あるいは不公平と断じることは難しいでしょう。むしろデータによって人を評価する社会の広がりの中で、保険という制度がどのように変容しているのかを考える材料と位置づけることができそうです。最終的に重要なのは、自分は何を公平と感じるのかという問いかもしれません。
【テーマ】
テレマティクス保険は公平性を高めるのか。
運転データに基づいて保険料を算定する仕組みが、
従来型のリスク分類と比べてどのような「公平/不公平」を生み出しているのか、
AIの視点から冷静かつ構造的に整理・考察してください。
【目的】
– 「データ活用は正義」あるいは「監視社会化」という単純な賛否に回収せず、制度の構造として整理する
– 保険における「公平性」とは何かを再定義する視点を提示する
– 読者がデータ社会における自己責任・監視・評価の関係を考える材料を提供する
【読者像】
– 一般社会人(20〜50代)
– 自動車保険に加入している、または加入を検討している人
– データ活用やプライバシー問題に関心を持つ層
– AIや保険制度に詳しくはないが、無関係ではいられないと感じている人
【記事構成】
1. 導入(問題提起)
– 「安全運転なら保険料が安くなる」という直感的な公平感を提示する
– 同時に、「常時データ取得」という構造への違和感も示す
– なぜテレマティクス保険が今注目されているのかを簡潔に説明する
2. 従来型保険の公平性とは何だったのか
– 年齢・性別・等級・地域など属性ベースのリスク分類を整理する
– 統計的公平(集団単位の公平)の仕組みを説明する
– なぜ「一部の人にとっては不公平」と感じられてきたのかを構造的に示す
3. テレマティクス保険がもたらす新しい公平
– 行動データに基づく個別評価の特徴を整理する
– 「結果」ではなく「過程(運転行動)」を評価する構造に触れる
– 情報の非対称性(保険会社と契約者の情報格差)がどのように変化するかを説明する
– ※具体例を挙げてもよいが、断定的な表現は避けること
4. 見落とされがちな新たな不公平
– 測定できる行動だけが評価対象になる問題
– 夜間勤務や長距離通勤など、構造的条件がリスクとして反映される問題
– データ取得とプライバシーの緊張関係
– 「公平の高度化」が「自己責任の強化」に接続する可能性を整理する
5. 公平性とは「誰にとっての公平」か
– 個人単位の公平と社会全体の公平の違いを説明する
– 保険制度の本質(相互扶助とリスク分散)に触れる
– データ社会における評価のあり方を再考する視点を提示する
6. まとめ
– テレマティクス保険は単純に公平/不公平と断じられないことを再確認する
– データによる評価社会の一断面として位置づける
– 読者が「自分は何を公平と感じるのか」を考える余白を残して締めくくる
【文体・トーン】
– です・ます調
– 煽情的・断定的にならず、冷静で構造的
– 専門用語は使用してよいが、必ず簡潔な補足説明を入れる
– 「不安を煽る記事」ではなく、「考える材料を提供する記事」とする
【執筆スタンス】
– 本記事は、正解や結論を断定するものではなく、
複数の要因や構造を整理したうえでの「考察」として執筆する
– 特定の立場・価値観を押し付けず、
読者が自分で判断するための材料を提示することを重視する
【出力形式】
– Markdown形式で出力する
– 小見出し(###)を多めに使用する
– 文字数は2000〜2500字を目安とする
– 記事末尾に「タイトル案」を3つ提示する
【タイトル案に関する重要な指示(厳守)】
– タイトル案は必ず「主タイトルのみ」を出力すること
– サブタイトル・説明文・補足文は一切付けないこと
– 記号(―、──、—、:、| 等)による分割は禁止
– タイトルは1文構成とし、文を分割しないこと
– 説明的・総括的・煽情的な表現は禁止
– 「問い」の形を基本とし、読者に思考の余白を残すこと
– 文字数は25〜35文字程度を目安とする
– 抽象語のみで終わらず、問いの対象が分かる表現を必ず含めること
– 参考タイトルと同一、または類似度の高い表現は使用しないこと
– 条件を満たさないタイトルは出力しないこと
【補足指示】
– 構造整理や概念整理が有効な箇所では、以下のようなコメントを挿入してよい
※(図:従来型保険とテレマティクス保険の比較構造)
※(図:個人単位の公平と集団単位の公平)
【参考タイトル(※構造参考のみ/出力・言い換え・再利用は禁止)】
「データで決まる保険料は本当に公平か?」
【バージョン情報の出力】
記事本文・タイトル案のあとに、必ず以下の形式で
「AIバージョン情報」を追記してください。
(不明な項目は「不明」と記載すること)
—
AIバージョン情報
– ベンダー:
– モデル名:
– モデルバージョン:
– 回答日時:
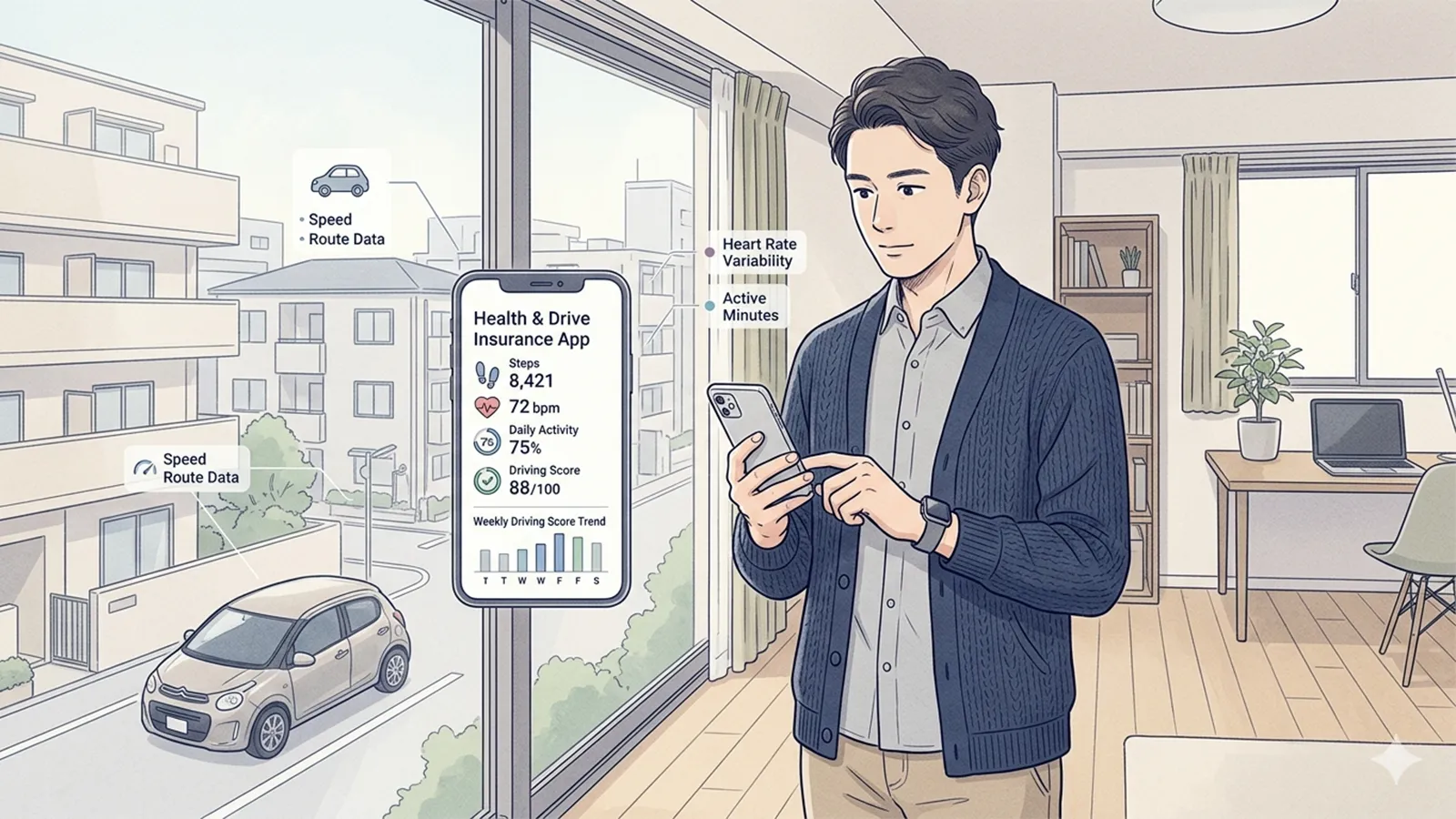
「安全運転なら保険料が安くなる」と聞くと、多くの人は直感的に公平だと感じるかもしれません。事故を起こす可能性が低い人が、より少ない負担で済むという仕組みは、合理的にも思えます。
一方で、テレマティクス保険は、車載機器やスマートフォンを通じて運転データを取得し、その内容をもとに保険料を算定します。ブレーキの頻度、急加速の有無、走行時間帯などが記録されることもあります。この「常時データ取得」という構造に、ある種の違和感を抱く人も少なくありません。
データ活用が進む社会において、保険もまた変化しています。では、この仕組みは本当に「公平性」を高めているのでしょうか。ここでは、賛否を急がず、その構造を整理してみます。
—
## 従来型保険の公平性とは何だったのか
### 属性に基づくリスク分類
従来の自動車保険では、年齢・性別・等級・地域などの属性がリスク分類の基準とされてきました。これは、過去の事故統計をもとに、特定の集団がどの程度の事故率を持つかを推計する仕組みです。
このような方法は「統計的公平」とも呼ばれます。個人ではなく、集団単位でリスクを評価し、その平均値を保険料に反映させる考え方です。
※(図:従来型保険とテレマティクス保険の比較構造)
### なぜ不公平と感じられてきたのか
しかし、20代という理由だけで保険料が高く設定される場合、実際に慎重に運転している人にとっては「自分の行動が評価されていない」と感じられることがあります。
この違和感は、集団単位の公平と個人単位の公平のズレから生じます。従来型保険は、相互扶助の原理に基づきつつも、個々の事情を十分に反映できないという構造を持っていました。
—
## テレマティクス保険がもたらす新しい公平
### 行動に基づく個別評価
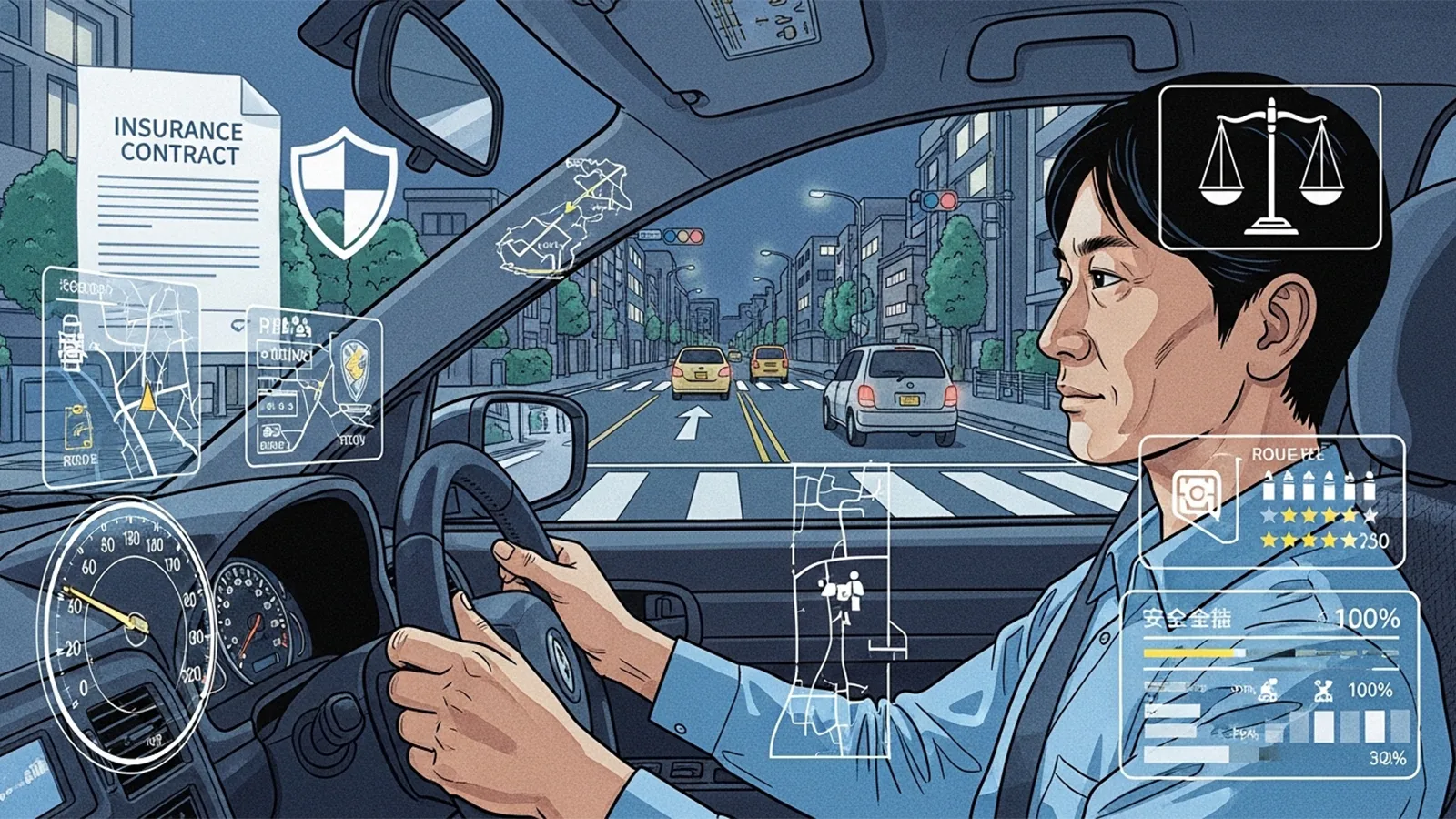
テレマティクス保険では、実際の運転行動が評価対象になります。これは、属性ではなく「行動データ」に基づく個別評価への転換と言えます。
ここでは、「事故という結果」だけでなく、「運転の過程」が評価されます。急ブレーキや速度超過といった具体的行動がスコア化され、それが保険料に反映される場合もあります。
### 情報の非対称性の変化
従来、保険会社は契約者の実際の運転状況を詳細には把握できませんでした。これを「情報の非対称性」と呼びます。つまり、契約者のほうが自分のリスクをよく知っている状態です。
テレマティクス保険は、この非対称性を縮小させます。保険会社がより多くの情報を得ることで、リスク評価の精度が高まる可能性があります。同時に、契約者側も自らの運転傾向を可視化できるという側面があります。
こうした仕組みは、個人単位の公平を高める方向に働くとも考えられます。
—
## 見落とされがちな新たな不公平
### 測定可能な行動だけが評価される
ただし、データ化できる行動だけが評価対象になるという構造もあります。慎重な判断や周囲への配慮といった要素は、数値化が難しい場合があります。
評価可能性そのものが、何を「良い運転」とみなすかを規定してしまう可能性もあります。
### 構造的条件の反映
夜間勤務者や長距離通勤者は、走行距離や時間帯の影響でリスクが高く評価される場合があります。これは個人の努力では変えにくい条件が、リスクとして反映される構造です。
この点では、行動ベースの評価もまた、社会的条件を内包しています。
### プライバシーと自己責任の接続
常時データ取得は、プライバシーとの緊張関係を伴います。どこまでの情報が収集され、どのように利用されるのかは重要な論点です。
さらに、「正しく行動すれば安くなる」という仕組みは、「正しく行動しないのは自己責任」という解釈に接続する可能性もあります。公平性の高度化が、責任の個人化を強める方向に働くかどうかは、制度設計次第と言えるでしょう。
—
## 公平性とは誰にとっての公平か
### 個人単位と社会全体の視点
個人単位の公平とは、各人のリスクに応じて負担が調整されることです。一方で、社会全体の公平とは、リスクを広く分散し、誰もが加入しやすい環境を維持することでもあります。
※(図:個人単位の公平と集団単位の公平)
保険の本質は、相互扶助とリスク分散にあります。過度に個別化された評価が進むと、リスクの高い人が排除される可能性も考えられます。
データ社会における評価は、効率性と包摂性のあいだで揺れ動きます。テレマティクス保険もまた、その一断面と捉えることができます。
—
## まとめ 評価社会のなかの保険
テレマティクス保険は、従来型よりも個別化された評価を可能にする仕組みです。その点で、ある種の公平を強化する側面があります。
同時に、測定可能性への依存やプライバシーの問題、自己責任の強化といった新たな論点も生み出しています。
この制度を単純に公平あるいは不公平と断じることは難しいでしょう。むしろ、データによって人を評価する社会の広がりの中で、保険という制度がどのように変容しているのかを考える材料と捉えることができそうです。
最終的に重要なのは、「自分は何を公平と感じるのか」という問いかもしれません。
—
## タイトル案
テレマティクス保険は公平をどう変えるのか
運転データ評価は保険の公平性を再定義するのか
行動データで決まる保険料は誰にとって公平か
—
AIバージョン情報
– ベンダー: OpenAI
– モデル名: GPT-5
– モデルバージョン: 不明
– 回答日時: 2026-02-25
本サイトの編集方針については「編集方針・AI利用ポリシー」をご覧ください。